This article was written by an SRES functional safety expert and examines how redundancy architectures shape system behavior in safety-critical applications, including the tradeoffs between fail-over and parallel designs, the risk of latent failures, and why redundancy alone is not sufficient to ensure system safety.
Looking to go deeper? SRES provides expert-led functional safety training, including certificate-based programs, as well as hands-on consulting support to help organizations implement ISO 26262 and related functional safety requirements across the product lifecycle.
Redundancy is a fundamental concept in the design of safety-critical systems. While often simplified as adding backups, the choice of redundancy architecture has a direct impact on system behavior, risk, and how failures manifest—particularly for functions that must operate continuously.
An important consideration when developing fault-tolerant systems is choosing an appropriate redundancy architecture for functions that require continuous operation.
A Tale of Two Failures
For an illustrative example, consider a system of an enclosed room where we are doing work that requires illumination – a surgical operating room for example. We have a power source, a switch, and a light source. When the switch is closed, we want the room to be illuminated. If we can’t turn the light on when we enter the room we might be annoyed, but we haven’t started work yet so our “critical” work isn’t interrupted. If the lights suddenly fail while in the middle of a critical procedure, however, the consequences are dire.
Image credit: National Standby — https://nationalstandby.com/wp-content/uploads/2018/04/power-outage-medical-facility.jpg
To protect against this high-risk failure, we perform an analysis by considering the basic situations:
We can’t turn on the lights before starting work (annoying, but not hazardous)
We can turn on the lights to start, and:
a. They stay on the whole time (nominal)
b. They turn off during our work time (hazardous)
When we are done working, the lights
a. Turn off when we want (nominal)
b. Are stuck on even when we try to turn them off (annoying, but not hazardous)
To ensure we have lights during the entire work period, redundancy is added: instead of a single lamp, we have two. We can even power each lamp with its own power source. This means that if one lamp burns out, or one power source fails, we won’t be left in the dark.
Types of Redundancy Architectures
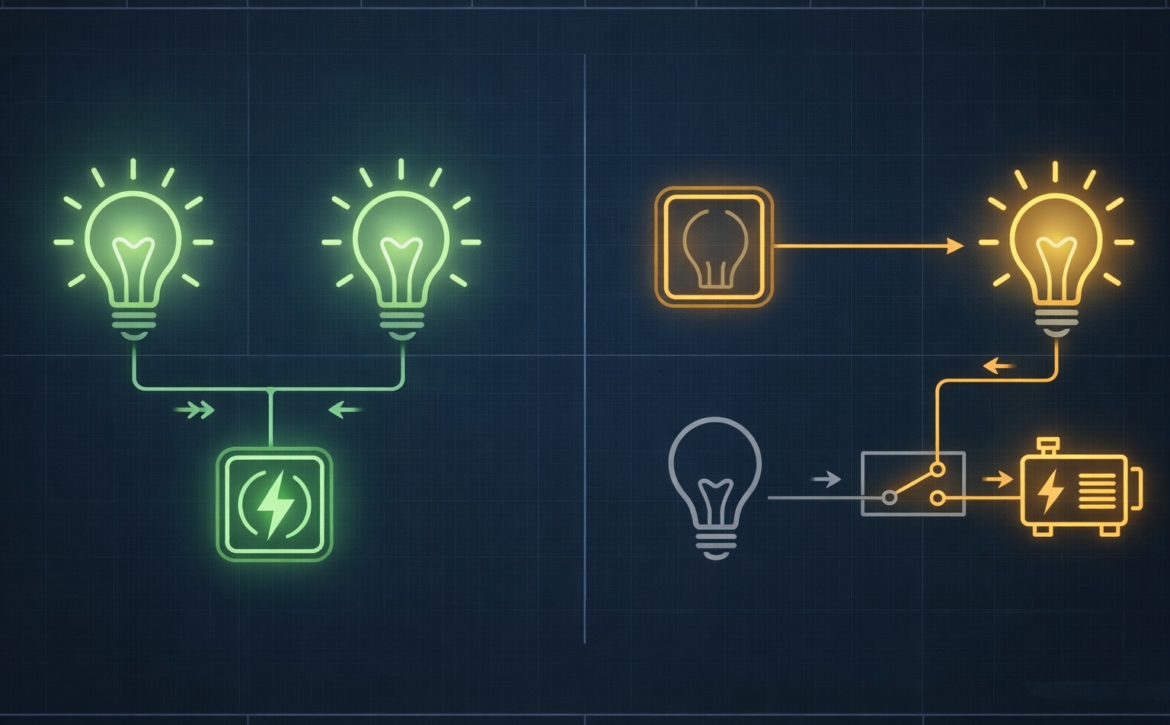
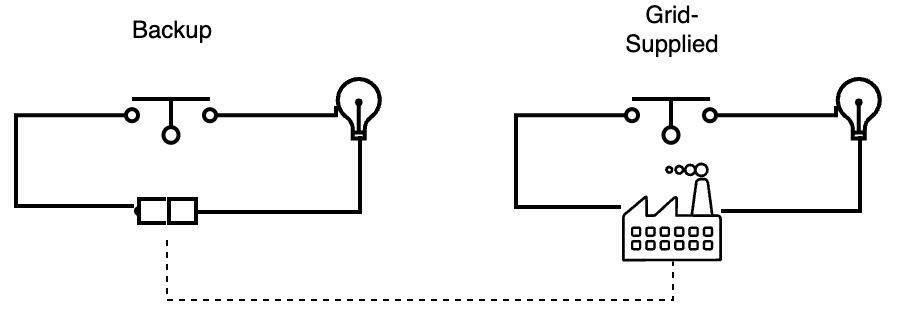
To gain further confidence that we won’t lose our lights, we need an understanding of the nature of the “backup” system and the two lamps. There are two general types of redundancy:
Fail-over redundancy: One lamp is used to start, and only if that light turns off during our work do we try to turn on the other lamp. In our lamp system, this might be due to, for example, use of a backup generator to power the second light, where that generator only turns on if the main power supply fails.
Parallel redundancy: both lamps should be running the whole time we are using the system. We know immediately if there is a problem with one lamp because if it doesn’t light initially, or if it burns out during our work, we notice it right away.
The type of redundancy employed is driven by considerations of cost, complexity, and risk mitigation. In our example with a fail-over generator, we might find that we need to run the generator during our procedure so we know it is working – we might not be able to risk the generator failing to start during a procedure. This has an operating cost though – we would be burning fuel even if it’s not necessary for illumination. On the other hand, perhaps a battery reserve system is used instead of a generator; this doesn’t have as high an operating cost as a generator because the battery can be “always on.” However, batteries have failure modes where they can appear to have full capacity when “charging” but may have far less charge than assumed.
Latent Failures and Observability
The inability of a generator to start “on demand,” a battery with reduced capacity, and a lamp that fails while it is off (so we don’t know it’s off until we try to use it) are examples of latent failures – that is, things that have failed but we don’t know it until we try to “use” them.
Engineers must reduce the risk associated with latent failures. Some systems can be constructed to eliminate latent failures entirely, like our lighting example. Our lighting example is one such system because, while perhaps costly, we can “run” both lights at the same time to minimize the risk. While this doesn’t eliminate the possibility of the generator or battery failing while in use, we can analyze the system to know the risk associated with how much time we can operate on the backup if the main system fails.
When Redundancy Isn’t Sufficient
Some systems do not afford the ability for parallel redundancy. Many automotive systems fall into this category.
Airbag System
In an airbag system, there is no way to know with certainty if an airbag will fire when needed because if we tried to make it fire, it would! It’s also infeasible to incorporate two airbags into every location. The risk could be minimized by making certain components redundant – for example an airbag might include two igniters. However, two igniters would not mitigate chemical degradation. One might envision two completely independent inflaters – but would this change the performance characteristics of the airbag? For systems susceptible to latent failures that don’t have a feasible redundancy architecture, solutions usually include a combination of durable design, prognostics, and/or inspection and replacement schedules.
Automated Emergency Braking (AEB)
In normal scenarios we do not intentionally cause the system to intervene so how do we know it would, in fact, intervene if necessary? This is a complex interaction between object detection and brake actuation systems. Vehicle user interfaces often don’t include – and the general population would likely be distracted by – visualization of run-time information that might yield some confidence in the system. For example, a display could show all detected objects continuously, giving an indication of system availability. Even if the detection system has risk mitigated by providing this information, there is a probability the actuation system fails even if an imminent collision is detected.
In addition to the redundancy architecture, the range of performance afforded by the redundancy should also be considered. In our lamp example from earlier – does the backup lamp have the same illumination as the main lamp? If we normally have two lamps, and one goes out, is the remaining illumination sufficient? Thus, even if our desired function is not lost entirely, but is merely degraded, we may need to specify some procedures or limitations to minimize risk associated with the degraded performance.
Some Tradeoffs Related to Redundancy Architecture
“Fail-Over” redundancy (backup)
“Parallel” redundancy (both “always working”)
Latent Failure Risk
Higher; both in the backup function failing and in the portions that ‘shut off’ the malfunctioning part.
Lower; mostly only the portion that ‘shuts off’ a malfunctioning part.
Resource Usage
Lower; the “standby” part uses fewer resources.
Higher; having multiple systems running may have higher resource use (energy, wear-out, etc.).
Coordination Aspects
Involves handoff logic, robustness of the “selection” logic.
Involves coordination of the working parts.
Selecting a Redundancy Architecture
Simply put, selecting a redundancy architecture is more than just “double up on components.” The use case, economics, and potential for latent failures must all be considered to select an appropriate redundancy architecture. Note also this is just an introduction to redundancy; within the “fail-over” and “parallel” redundancy concepts there are many variations. Fail-over may have a designated primary vs backup system, or the solution may utilize wear-leveling where each element is made “primary” for roughly equal portions of operating time. Parallel redundancy systems may be dual- or even triple-redundant systems.
Have insights or questions? Send us an email at info@sres.ai or leave a comment below—we welcome thoughtful discussion from our technical community.
Interested in learning more about our approach? Explore why teams choose SRES training and how we help automotive organizations with consulting support across functional safety, cybersecurity, autonomy safety, and EV development.